Performed the key logger setup as described in previous article, but instead of just running the hollows_hunter in command prompt, let’s perform detailed examination in the debugger.
Here is the call leading to the IAT hooks count in hollows_hunter:

It is in \hollows_hunter\pe-sieve\scanners\scan_report.cpp. It will eventually leads to a call to countResultsPerType(type, SCAN_SUSPICIOUS). Inside this function, there is a class called reportsByType and each type has module set and each has a status in it. As you can see from the picture below, it is of type ModuleScanReport.
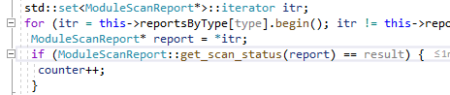
So, if the status is SCAN_SUSPICIOUS, meaning that the module is marked as suspicious, it will increase the counter.
In my case of testing program (see previous article), the module marked as suspicious is C:\Windows\System32\imm32.dll
From the above picture, The reportsByType object is of type pesieve::IATScanReport. Let’s checked the mechanism of how it mark the status as suspicious.
The suspicious status for the IAT hook is coming from pesieve::IATScanner::scanRemote inside \hollows_hunter\pe-sieve\scanners\iat_scanner.cpp.
It is based on the having the not_covered class of type ImpsNotCovered count is greater than zero:

But first I have to understand how the remoteModData object is initialized, because it is this object that is being analyzed for presence of IAT hook. This object is initialized in \hollows_hunter\pe-sieve\scanners\scanner.cpp as follow:

The processHandle is the process handle of the process being examined, in this case is the test program that contains windows key logger hook.
The hMods is an array of imported modules and the counter depends on the value of modules_count which is initialized at:

As you can see, the above variable (modules_count) is depended upon enum_modules (\hollows_hunter\pe-sieve\utils\modules_enum.cpp) which is using the EnumProcessModulesEx Windows API:

The first module in the module list is the main process itself and it is stored in modData object as well as other modules., but I notice there’s a discrepancy in the size (original_size) field when it is compared to the actual file size. For example the main process file size is actually 1510912 bytes but it is recorded as 2097152 bytes:

The value of 2097152 is calculated from payload_nt_hdr->OptionalHeader.SizeOfImage:

The source is in \hollows_hunter\pe-sieve\libpeconv\libpeconv\src\pe_raw_to_virtual.cpp with the call stack that as follows:

Now back to when the remoteModData is used for analysis at \hollows_hunter\pe-sieve\scanners\iat_scanner.cpp:

So here, there are no information about which module name being analyzed, only the imgBufferSize that is being propagated from the SizeOfImage data item. This will cause confusion as to which module is actually being analyzed. It is after some further steps in digging that I realized there’s some connection between modData and remoteModData.
In this case, when performing the debugging step through the above location, besides the remoteModData, you can view the corresponding modData for more information about the module name.
But it should be noted that remoteModData is the in memory module, where as modData is the module that is retrieved from disk.
Now back to the mechanism to check for IAT hook, as you can see, it is based from presence of not_covered count. This value is modified at the call to peconv::fix_imports(vBuf, vBufSize, exportsMap, ¬_covered).
The above function is defined in \hollows_hunter\pe-sieve\libpeconv\libpeconv\src\fix_imports.cpp
You notice that in fix_imports method, it is consuming the exportsMap object. Let’s find out how the exportsMap is initialized by examining the call stack that leads to the fix_imports call:

The exportsMap is passed as a parameter during the scanRemote, but checking into this routine, the initialization process is not found, so other means to finding this object should be devised, and it is located in the IATScanner class object constructor:

Here is the exportsMap parameter that’s get passed to the IATScanner:

It is in \hollows_hunter\pe-sieve\scanners\scanner.cpp and passed from the process_report object that is a parameter for scanForIATHooks method. the process_report is of ProcessScanReport class and it is initialized when the given module list has the export function in add_to_lookup method:

The modData.original_module parameter is the raw image data. This is inside add_to_lookup method as follows, it is defined in \hollows_hunter\pe-sieve\libpeconv\libpeconv\src\exports_mapper.cpp:

The currFunc contains the function information such as name and the callRVA is the RVA of the address of the actual function body. The add_function_to_lookup function will add the exportsMap data accordingly. In the end exportsMap will contain usable export function information to be used in the verification process of import function of the process to each corresponding export function list.
The call_via_ptr will be calculated from the import table of the running process using FirstThunk by adding the RVA of each entry to the module base address. This is an example of the address pointer of the call_via_ptr:

The address is the RVA + base address of the modules in the process. As you can see, the content is 0x7732c450, this will be checked to the exportsMap in the method below:

It is declared in \hollows_hunter\pe-sieve\libpeconv\libpeconv\include\peconv\exports_mapper.h. The va itself in exportsMap is calculated by adding the RVA of export table to the moduleBase which is actually the module handle value (HMODULE).
In the above example the import address 0x7732c450 is corresponding to GetWindowTextA of user32 library. When the imported function address it is found in the export list, it will added to the addresses list for further checking, which will be updating the notCovered object variable.
The notCovered is updated in the ImportsUneraser::uneraseDllImports method as follows:

The variable dllCoverage.addrToFunc is the list of imported addresses, which is the addresses from the above. Inside ImportsUneraser::fillImportNames, the notCovered object is updated as follows:

This function resides in \hollows_hunter\pe-sieve\libpeconv\libpeconv\src\imports_uneraser.cpp with the call stack that leads to the above call as follows:

The addr_to_func object is obtained from all export functions in the disk file per module (for example user32.dll) and the searchedAddr is the import address from the memory. So, when the searchedAddr is not found in the addr_to_func object, there is a modification in the process memory for the related import address and the notCovered object is added. When this count is greater than zero, it will added to IAT hook report.
The reason that hollows_hunter reports IAT hook is that when the import addresses list from kernel32.dll in imm32.dll is cross checked to the addr_to_func list, it is not found in the list. But by performing the offline check using actual import address of the DLL file, for example using IDA disassembler, reveals 61 import addresses, whereas the addr_to_func list for kernel32.dll is 60, so missing 1 (one) item that is reported by hollows_hunter.
Let’s perform detailed examined of how addr_to_func is populated in hollows_hunter. The addr_to_func is derived from addrToFunc variable inside dllCoverage object:

As you can see from the above picture, it results in 60 items, missing one item. The addrToFunc itself is updated inside the call to map_addresses_to_functions. Here is the call stack to this function at the time when the module is imm32.dll and the imported dll from imm32.dll is kernel32.dll:

And here is the cause of the missing one item in the addrToFunc list:

The given address is 1963722320 (0x750C0650). This import address from kernel32.dll is then cross checked to exportsMap object using find_exports_by_va. The found object is then cross checked to the library name, and it is compared to the chosenDll. From the above case, the chosenDll is “kernel32” but when it is cross checked to the all exports object, the corresponding address is belong to “kernelbase”.
hollows_hunter application will make a report as follows:
1b048;kernel32.GetProcessMitigationPolicy #696->kernelbase.GetProcessMitigationPolicy #692;74fb0000+110650;0
The address 74fb0000+110650 when calculated points to kernelbase.GetProcessMitigationPolicy (0x750C0650), whereas the value 0x1b048 is from the notCovered.thunkToAddr or the RVA (address location) of import entry. In this case, the RVA is starting at 0x1B000 and 0x1B048 is the location which contain 0x750C0650 that hollows_hunter marked as IAT hook, because it has different DLL name when compared with the export list.
The left hand side of imported function name of kernel32.GetProcessMitigationPolicy is retrieved from the exportsMap list.
Actually there’s a same export function name for GetProcessMitigationPolicy for both in kernel32.dll and kernelbase.dll and for some reason, the windows itself perform the IAT patch for this function to use the one inside kernelbase.dll instead of kernel32.dll.








































































































